Компанія DeepMind випустила нову модель штучного інтелекту — MuZero — і вона здатна опановувати ігри на ходу, не знаючи їхніх правил. MuZero може грати у стратегії (на кшталт Ґо, шахів і Сьоґі) й у візуально складніші відеоігри Atari.
Раніше DeepMind створювала ШІ, які знали правила ігор й успішно перемагали людей. Наприклад, AlphaGo, випущена у 2016 році, обійшла чемпіона гри в Ґо. Ця модель вчилась завдяки тому, що аналізувала професійні й аматорські змагання серед гравців-людей.
Наступна версія, AlphaGo Zero (2017), могла експериментувати й не використовувати дані про чужі ігри, вона тренувалась на матчах проти самої себе. Alpha Zero (2018) вже грала не лише в Ґо, а й в шахи та Сьоґі — у той самий спосіб. Але усі вони мали хоча б основні правила, на базі яких і шукали стратегії виграшу.
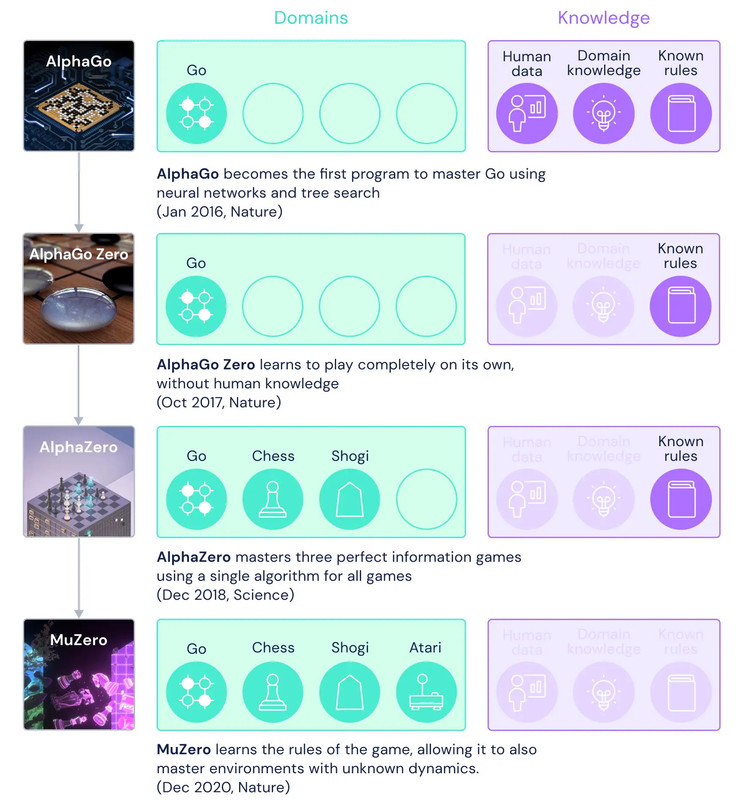
Видання Techcrunch наводить таку аналогію: якщо ви знаєте, що пішак може стати ферзем, то плануєте це з самого початку. Якщо ж це ще потрібно з'ясувати, то й стратегію ви можете розробити зовсім іншу.
MuZero вчиться грати самостійно, без даних про чужі матчі, і водночас вона не знає навіть базових правил гри. Це зручно в тому сенсі, що проблеми реального світу теж складно об'єднати набором простих правил, тож такий штучний інтелект зможе краще впоратись зі справжніми задачами.
Зараз за допомогою MuZero дослідники хочуть покращити алгоритми стиснення відео. Детальніше про MuZero можна дізнатись у виданні Nature.

Ще немає коментарів