В стандарті С++11 існує поняття лямбда-вираз. Тим, хто читає документацію та статті в інтернеті про лямбда-вирази, важко розібратися, що це за вирази, як їх використовувати та які їхні особливості. Одні джерела поверхово описують тему, а інші навпаки – занадто складно. На мою думку, це предмет вивчення не для новачків. Але в цій статті я постараюся максимально доступно пояснити, що таке лямбда-вирази.
В математиці лямбда-численням називають систему для дослідження визначення та застосування функції. Таким чином математики спростили формат запису функції і намагалися формалізувати обчислення. В нас є такий вираз:
λх.х
Де λ означає, що це лямбда-функція. Після цього перша «х» - список аргументів, в яких може бути інша лямбда-функція. «х» після крапки – тіло функції, а вже після нього іде аргумент, який передається. Наприклад,
λх.х+2 5
В результаті повернеться 7, оскільки 5 передається в якості аргументу, тому 5+2 = 7. З цього можна зробити висновок, що будь-яка змінна – лямбда-вираз. Детальніше у Вікіпедії.
Перед тим як почати розбір лямбда-виразу в програмуванні, давайте згадаємо що таке функтор. В різних мовах програмування цей термін може мати різне значення. В мові С++ функтор – скорочена назва від «функціональний об'єкт». Функтор являє собою екземпляр, в класі якого визначено перевантажений operator() . Розглянемо приклад:
class Functor
{
public:
Functor();
void operator()() const;
};
Functor::Functor()
{
}
void Functor::operator()() const
{
cout << "Hi, I am functor." << endl;
}
int main()
{
Functor funObj;
funObj();
}
У класі Functor оголошений перевантажений operator() . В функції main() створюється об'єкт класа Functor з іменем funObj . Цей об'єкт і є функтором. Після створення об'єкта ви бачите вираз funObj() – використання функтора. В результаті на вивід ми отримаємо повідомлення > «Hi, I am functor.».
Що ж, з функтором розібралися. Мабуть, у вас виникло запитання, при чому функтор і лямбда-вирази? Відповідь проста.
Іншими словами лямбда-вираз – безіменна локальна функція. І щоб краще зрозуміти значення «безіменна функція» та «анонімний функтор», розглянемо наступний код.
void output(int i) // функція output() не може бути перевантажена, оскільки виникне помилка в for_each
{
cout << i << " ";
}
void outputVec(vector<int>& vec)
{
for (vector<int>::iterator iter = vec.begin(); iter != vec.end(); ++iter)
cout << *iter << " ";
cout << endl;
}
int main()
{
vector<int> myVector;
for (int i = 0; i < 10; ++i)
myVector.push_back(i);
outputVec(myVector); // вивід за допомогою звичайної функції
for_each(myVector.begin(), myVector.end(), output); // 1
cout << endl;
for_each(myVector.begin(), myVector.end(), [](int i) //2
{
cout << i << " ";
}
);
cout << endl;
return 0;
}
В цій програмі створюється вектор і заповнюється числами від 0 до 9.
В рядку 1 в for_each() викликається функція з іменем output, яка виводить вміст вектора. В рядку 2 використовується функція for_each(), яка приймає посилання на безіменну функцію, тобто лямбда-вираз. В усіх випадках ми отримуємо однаковий результат: 0 1 2 3 4 5 6 7 8 9.
Як вже було згадано, функтор є екземпляром класу, в якому перевантажений operator(), а лямбда-вираз – скорочена форма анонімного функтора. В наступному прикладі представлене порівняння:
class Anonim
{
public:
void operator()(int _value) const;
};
void Anonim::operator()(int _value) const
{
cout << _value << " ";
}
int main()
{
vector<int> myVector;
for (int i = 0; i < 10; ++i)
myVector.push_back(i);
for_each(myVector.begin(), myVector.end(), Anonim()); // 1
cout << endl;
for_each(myVector.begin(), myVector.end(), [](int _value) //2
{
cout << _value << " ";
}
);
cout << endl;
return 0;
}
В рядку 1 у функцію передається анонімний функтор класу Anonim – Anonim(), який виводить елементи вектора.
В рядку 2 передається лямбда-вираз, який є скороченою формою запису анонімного функтора Anonim() і теж виводить елементи вектора. Такий підхід з лямбда-виразами дозволяє уникати створення класів і спрощує процес написання коду.
Структура лямбда-виразів
Зазвичай, лямбда-вираз має таку структуру:

По замовчуванню функція лямбда-виразу повертає тип void. Тобто, дану вище структуру можна записати так:
[]()->void {}
Це означає, що ми можемо явно вказувати тип повернення за допомогою такого синтаксису:
[]()-><тип> {}
Розглянемо приклад:
int main()
{
vector<int> myVector(10, 5);
for_each(myVector.begin(), myVector.end(), [](int _value)
{
cout << _value << " ";
}
);
cout << endl;
return 0;
}
В прикладі створюється вектор і одразу ініціалізується 10-ма значеннями «5». Після цього виконується фукція for_each і, як ви побачили, використвується лямбда-вираз. Список захоплення [ ] порожній (його розглянемо пізніше), а от в списку параметрів приймаєтся _value, що є елементом вектору. Компілятор розуміє, що функція повертає тип void, оскільки ми не вказали явно інший тип і не використовуємо оператори return. Результат програми – 5 5 5 5 5 5 5 5 5 5.
Ми можемо не вказувати тип повернення функції лямбда-виразу, якщо він void або якщо функція використовує один оператор return – тоді компілятор сам визначає який тип повертати.
int main()
{
vector<int> myVector(10, 5);
bool sum;
sum = count_if(myVector.begin(), myVector.end(), [](int _value)
{
return (_value + 3) == 8;
}
);
cout << sum << endl;
return 0;
}
В програмі заповнюється вектор 10-ма елементами із значенням 5. В функцію count_if() посилається лямбда-вираз, який має один оператор return, в якому перевіряється умова чи додавання до елемента вектора значення 3 буде рівно 8.
В цьому випадку компілятор визначить тип повернення як bool, що є аналогічним такому запису:
int main()
{
vector<int> myVector(10, 5);
bool sum;
sum = count_if(myVector.begin(), myVector.end(), [](int _value)-> bool
{
return (_value + 3) == 8;
}
);
cout << sum << endl;
return 0;
}
Якщо ж кількість операторів return 2 і більше, то тип необхідно вказати явно, адже в іншому випадку компілятор не зможе інтерпретувати який тип повертати. Явне вказування типів, як ви вже знаєте, має вигляд:
[]()->bool {}
[]()->int {}
[]()->double {}
...
Список захоплення [ ]
Список захоплення призначений для захоплення змінної, яка існує в тій же зоні видимості, що і лямбда-вираз. Наприклад:
int main()
{
vector<int> myVector(10, 5);
int number1, number2;
cin >> number1;
cin >> number2;
bool sum;
sum = count_if(myVector.begin(), myVector.end(), [number1, number2](int _value)-> bool
{
return _value == (number1 + number2);
}
);
cout << sum << endl;
return 0;
}
Як бачимо, в [ ] захоплюються змінні number1 і number2 з зовнішнього контексту, які можна тепер використовувати в лямбда-виразі. Слід зауважити, що у лямбда-виразі використовуются копії цих змінних, а не їх оригінали. Для роботи з оригіналами використовується захоплення по посиланню [&], яке ми розглянемо трохи пізніше.
Тому для того, щоб мати змогу редагувати захвачені змінні слід використовувати специфікатор mutable.
int main()
{
vector<int> myVector(10, 5);
int number1, number2;
cin >> number1;
cin >> number2;
bool sum;
sum = count_if(myVector.begin(), myVector.end(), [number1, number2](int _value) mutable -> bool
{
number1 = number2 + number1;
return _value == (number1 + number2);
}
);
cout << sum << endl;
return 0;
}
Тепер, коли в цьому коді використовується специфікатор mutable, ми можемо переініціалізувати зовнішні змінні number1, number2 та виконувати операції над ними.
Крім того, ми маємо можливість спростити власне життя, використавши режими захвату. Є два режими:
[=]() {};
[&]() {};
[=] використовується для захоплення змінних по значенню. Всі змінні з зовнішнього контексту, які використовуються в тілі лямбда, автоматично захоплюються. Точніше захоплюється їхнє значення.
int main()
{
vector<int> myVector(10, 5);
int number1, number2;
cin >> number1;
cin >> number2;
bool sum;
sum = count_if(myVector.begin(), myVector.end(), [=](int _value) mutable -> bool
{
number1 = number2 + number1;
return _value == (number1 + number2);
}
);
cout << sum << endl;
return 0;
}
Це значно спрощує написання коду, оскільки при великій кількості захоплених змінних необхідно все прописувати вручну і лямбда-вираз стає дещо громіздким. Або ж виникає необхідність динамічного додавання змінної в тіло лямбди. Через це також існує ризик захопити непотрібну змінну.
[var1, var2, var3]() [=]()
{ {
var1; var1;
var2; == var2;
var3; var3;
} }
[&] використовується аналогічно до [=] за винятком, що це захоплення за посиланням.
[&]()
{
var1;
var2;
var3;
}
Якщо ми вказуємо [&], то зміна значення змінної в зовнішньому контексті відобразиться в тілі лямбда і навпаки, якщо ми змінюємо значення змінної в тілі лямбди - зміна відбудеться і в зовнішньому контексті. Слід зауважити, специфікатор mutable не обов'язково використовувати при операції над зовнішніми змінними в тілі лямбди.
При використанні [=] (змінити значення без mutable не можна) і зміні значень зовнішніх змінних в тілі лямбди ці змінні не змінюватимуться в зовнішньому контексті. Тобто, операції над зовнішніми змінними в тілі лямбди при захопленні по значенню відбуватимуться над копіями цих змінних, в той час як [&] працює з оригіналами.
Є такі варіанти використання режимів захоплення:
[]() {}; // без захоплення
[=]() {}; // всі змінні захоплюються по значенню
[&]() {}; // всі змінні захоплюються по посиланню
[var1, var2]() {}; // захоплення var1 і var2 по значенню
[&var1, &var2]() {}; // захоплення var1 і var2 по посиланню
[var1, &var2]() {}; // захоплення var1 по значенню, а var2 по посиланню
[=, &var1, &var2]() {}; // всі змінні захоплюються по значенню
// крім var1 і var2, які захоплюються по посиланню
[&, var1, var2]() {}; // всі змінні захоплюються по посиланню
// крім var1 і var2, які захоплюються по значенню
При такому виразі:
[=](int& _value) mutable -> {...};
У змінних, які захоплюються по значенню, буде мінятися їхня внутрішня копія, а от параметр _value передається по посиланню, тобто оригінал теж змінюватиметься.
Особливості лямбда-виразів
Розглянемо деякі особливості лямбда-виразів. Однією з особливостей є те, що лямбда-вираз не може захопити змінну у список захоплення, якщо ця змінна не просторі видимості. Цілком загальне правило, яке стосується не тільки лямбда-виразів.
int var1, var2, var3;
for (;;) for (;;)
int var1, var2, var3; var1, var2, var3;
[=]() mutable [=]() mutable
{ {
var1; var1;
var2; var2;
var3; var3;
} }
// wrong // right
Однак, якщо в нас є наступний випадок:
class Example
{
public:
Example(int value = 0);
void Output();
private:
int m_value;
};
Example::Example(int value) : m_value(value)
{
}
void Example::Output()
{
function<int(int)> lambdaSave = [m_value](int& _val) mutable -> int // error
{
_val = m_value;
return _val;
};
}
Тоді компілятор не допускає використання змінної m_value в лямбда-виразі, оскільки вона є членом даних (неважливо закритим, захищеним чи відкритим) і знаходиться поза зоною видимості. Для рішення цієї проблеми використовується вказівник this. Тепер даний код можна переписати таким чином:
class Example
{
public:
Example(int value = 0);
void Output();
private:
int m_value;
};
Example::Example(int value) : m_value(value)
{
}
void Example::Output()
{
auto lambdaSave = [this](int& _val) mutable -> int // error
{
_val = m_value;
return _val;
};
}
Зверніть увагу на вираз function<int(int)> lambdaSave і auto в прикладах. Незабаром ми до цього повернемося.

Генерація лямбда-виразів
Як ви помітили, в останньому прикладі використовується такий вираз - function<int(int)> lambdaSave. Цей вираз зберігає стан лямбда-виразу.
Для цього небхідно підключити відповідну бібліотеку:
#include <functional>
За допомогою цієї бібліотеки можна писати функції, які генерують лямбда-вирази і навіть лямбда-вирази, що також генерують лямбда-вирази. Звучить складно, але зараз ви все зрозумієте.
Структура такої функції має вигляд:

Приклад:
function<function<int(int)> (int)> Generation = [](int _value) -> function<int(int)>
{
return [_value](int _secondValue) -> int
{
return _value + _secondValue;
};
};
Тепер пояснення:
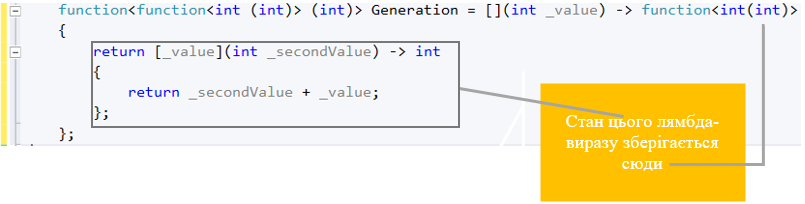
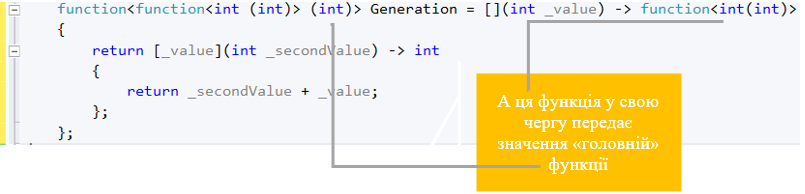
В результаті Generation зберігає стан _secondValue + _value. Це все досить складно і на практиці навряд чи використовуватиметься. Наведено як приклад, щоб ви мали уявлення.
Крім того, ми згадували auto. Ключове слово auto дозволяє автоматично визначати тип. Наприклад:
auto a = 5;
Тут компілятор автоматично визначить тип змінної a – int. Однак змінити тип в подальшому не можна. Тобто якщо переініціалізувати змінну а = 3.56, компілятор виведе число 3, так як він попередньо визначив тип а як int, а не float. За допомогою auto попередній код можна сильно спростити.
auto Generation = [](int _value) -> function<int(int)>
{
return [_value](int _secondValue) -> int
{
return _value + _secondValue;
};
};
Такий підхід реалізовує абстрагування і є практичним, оскільки програмістові не доведеться самому визначати типи.

Ще немає коментарів